Model explainability (XAI)¶
As BlueCast aims to support data scientist for real world applications, it offers various insights around the model itself.
Hyperparameter tuning¶
After hyperparameter tuning the progress of the loss metric is shown. This is useful to estimate if less tuning rounds would be sufficient in future runs or if even more tuning rounds are required.

Additionally, the most important hyperparameters are visualised. This can be used to decide which parameters to include in an extra GridSearch layer.

Model performance¶
When building a model, knowing the model performance is crucial to make model
and business decisions. Therefore all BlueCast classes offer a fit_eval function,
that tunes and trains a model like the fit method, and evaluates the model
on unseen data. At the end a confusion matrix and a list of metrics are shown:
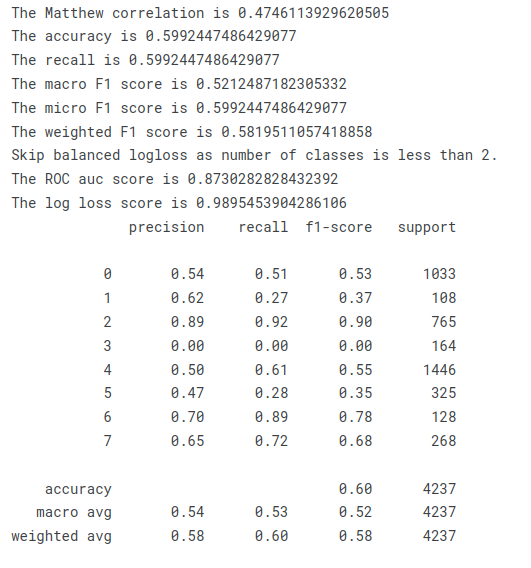
For CV classes the mean performance on all unseen dataset and the standard deviation of those will be shown as well.
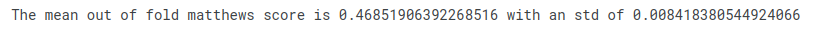
SHAP values¶
While understanding the tuning process is helpful, we also want to understand how the model behaves and which features are particularly important. Thus BlueCast makes use of SHAP values. First it will show the global feature importance:

Furthermore it will also show a sample on row level and plot waterfall plots of
SHAP values for each target clas of defined sample indices. User can change the
training config and adjust the shap_waterfall_indices parameter to pass a list
of indices instead.

The third visualization is the dependence plot, which shows feature interactions
and their impact on SHAP values on a certain feature. By default BlueCast shows
dependence plots for the top 5 features for each class. The number of features
can adjusted via customization of the show_dependence_plots_of_top_n_features
param in the training config.

The SHAP functions are part of all BlueCast classes and are called when using
the fit method.
This toolkit can also be used after model training for new data or for an external model.
from bluecast.evaluation.shap_values import (
shap_dependence_plots,
shap_explanations,
shap_waterfall_plot,
)
shap_waterfall_indices = [2, 35, 999]
class_problem = "binary" # or 'multiclass' or 'regression'
show_dependence_plots_of_top_n_features = 5
shap_values, explainer = shap_explanations(automl.ml_model.model, x_test)
shap_waterfall_plot(
explainer, shap_waterfall_indices, class_problem
)
shap_dependence_plots(
shap_values,
x_test,
conf_training.show_dependence_plots_of_top_n_features,
)
Once a model is on production we might want to have access to Shapley values
for the new data as well. For such cases the predict method of BlueCast
and BlueCastRegression has the parameter save_shap_values. If true BlueCast
will calculate and store the Shapley values for the unseen data, so they can be
further used.
from bluecast.evaluation.shap_values import shap_waterfall_plot,
preds = automl.predict(df, save_shap_values=True)
# plot the waterfall chart for row idx 5
shap_waterfall_plot(
automl.explainer, [5], "binary"
)
For CV classes it is required to access the stored sub models to plot the waterfall charts:
from bluecast.evaluation.shap_values import shap_waterfall_plot,
# chosing the 1st model
preds = automlbluecast_models[0].predict(df, save_shap_values=True)
# plot the waterfall chart for the rows idx 5, 8 and 123
shap_waterfall_plot(
automl.explainer, [5, 8, 123], "binary"
)
Plotting decision trees¶
How to plot decision trees will depend on the exact implementation. As BlueCast uses Xgboost by default, we illustrate the default way.
Increase verbosity during training¶
Bluecast wants to grant full visibility on model and training behaviour
while being as silent as possible. By default Bluecast keeps the verbosity
to a minimum and only shows the most important information. However, it is
possible to adjust the training configuration to increase verbosity and
show detailed information. Via show_detailed_tuning_logs BlueCast will
print the tested tuning parameter sets and their results for each tuning trial.
In the XgboostTuneParamsConfig and XgboostTuneParamsRegressionConfig configs
the verbosity can be adjusted to show the train and test set loss. Please
note that this will increase the size of notebook outputs significantly.
Accessing the trained models¶
Regardless of the model architecture used we need to know where BlueCast stores the trained model. The exact path differs between BlueCast(Regression) and Bluecast(Regression)CV classes as CV classes are a wrapper around BlueCast classes.
BlueCast classes¶
The BlueCast classes store their model in an ml_model attribute where the trained
model is a model attribute.
import matplotlib.pyplot as plt
from xgboost import plot_tree
plot_tree(automl.ml_model.model)
fig = plt.gcf()
fig.set_size_inches(150, 80)
plt.show()
BlueCastCV classes¶
BlueCast have two characteristics to pay attention two:
they are a wrapper around BlueCast classes
they usually store multiple BlueCast instances at once
The BlueCast instances are stored inside a list attribute bluecast_models:
import matplotlib.pyplot as plt
from xgboost import plot_tree
for model in automl.bluecast_models:
plot_tree(model.ml_model.model)
fig = plt.gcf()
fig.set_size_inches(150, 80)
plt.show()
This way we loop through all stored ml models and see the decision trees for each of them. This can reveal significant differences in the trees.
